Soy nuevo en las redes neuronales convolucionales y estoy aprendiendo la convolución 3D. Lo que pude entender es que la convolución 2D nos brinda relaciones entre características de bajo nivel en la dimensión XY, mientras que la convolución 3D ayuda a detectar características de bajo nivel y relaciones entre ellas en las 3 dimensiones.
Considere una CNN emplea capas convolucionales 2D para reconocer dígitos escritos a mano. Si un dígito, digamos 5, se escribió en diferentes colores:

¿Una CNN estrictamente 2D funcionaría mal (ya que pertenecen a diferentes canales en la dimensión z)?
Además, existen redes neuronales prácticas bien conocidas que emplean 3D ¿convolución?
Comentarios
- Las convoluciones 3D se utilizan comúnmente para procesar imágenes en 3D, como escáneres de resonancia magnética.
- ¿Hay publicaciones en arquitecturas 3D Conv?
- @Shobhit dada la respuesta de ashenoy, ¿hay alguna parte de su pregunta que aún no ha sido respondida?
Responder
Las CNN 3D se utilizan cuando desea extraer entidades en 3 dimensiones o establecer una relación entre 3 dimensiones.
Básicamente, es lo mismo que Convoluciones 2D, pero el movimiento del kernel ahora es tridimensional, lo que provoca una mejor captura de las dependencias dentro de las 3 dimensiones y una diferencia en o dimensiones de salida posteriores a la convolución.
El núcleo en convolución se moverá en 3 dimensiones si la profundidad del núcleo es menor que la profundidad del mapa de características.
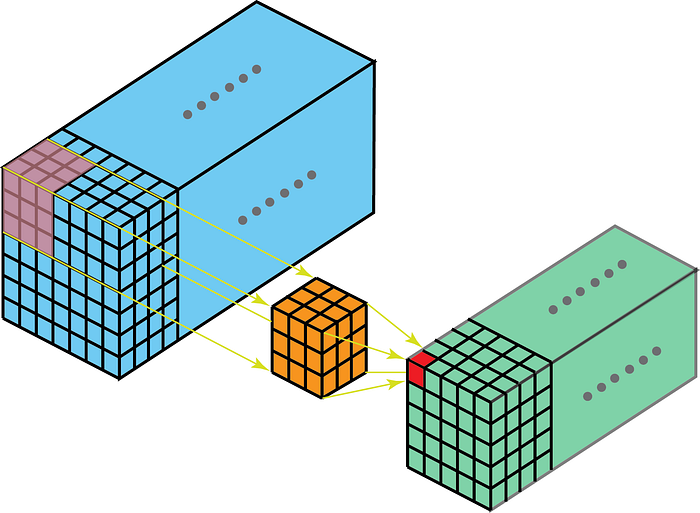
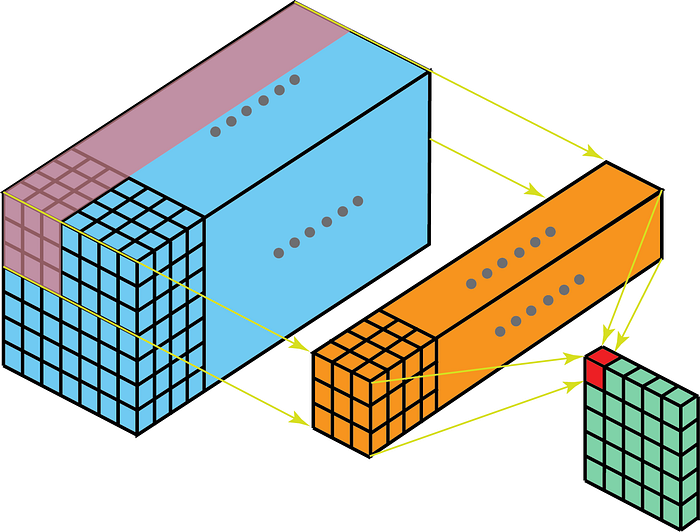
Por otro lado, las convoluciones 2-D en datos 3-D significan que el kernel solo atravesará 2-D. Esto sucede cuando la profundidad del mapa de características es la misma que la profundidad del kernel (canales)
Algunos casos de uso para una mejor comprensión son: exploraciones de resonancia magnética en las que se debe comprender la relación entre una pila de imágenes; y un extractor de características de bajo nivel para datos espacio-temporales como videos para reconocimiento de gestos, pronóstico del tiempo, etc. (las CNN en 3D se utilizan como extractores de características de bajo nivel solo en múltiples intervalos cortos, ya que las CNN en 3D no logran capturar a largo plazo Dependencias espacio-temporales: para obtener más información al respecto, consulte ConvLSTM o una perspectiva alternativa aquí . ) La mayoría de los modelos de CNN que aprenden de los datos de video casi siempre tienen 3D CNN como un extractor de funciones de bajo nivel.
En el ejemplo que mencionaste anteriormente con respecto al número 5, las convoluciones 2D probablemente funcionarían mejor, ya que estás tratando la intensidad de cada canal como un agregado de la información que contiene, lo que significa que el aprendizaje sería casi el lo mismo que en una imagen en blanco y negro. El uso de convolución 3D para esto, por otro lado, provocaría el aprendizaje de relaciones entre los canales que no existen en este caso (¡También las convoluciones 3D en una imagen con profundidad 3 requerirían una kernel poco común para ser utilizado, especialmente para el caso de uso)
¡Espero que su consulta haya sido borrada!
Respuesta
Las convoluciones 3D deberían utilizarse cuando desee extraer características espaciales de su entrada en tres dimensiones. Para la visión por computadora, se utilizan normalmente en imágenes volumétricas , que son 3D.
Algunos ejemplos son clasificación de imágenes renderizadas en 3D y segmentación de imágenes médicas