Ich bin neu in Faltungs-Neuronalen Netzen und lerne 3D-Faltung. Was ich verstehen konnte, ist, dass die 2D-Faltung Beziehungen zwischen Merkmalen auf niedriger Ebene in der XY-Dimension ergibt, während die 3D-Faltung dazu beiträgt, Merkmale auf niedriger Ebene und Beziehungen zwischen ihnen in allen drei Dimensionen zu erkennen.
Betrachten Sie a CNN verwendet 2D-Faltungsschichten, um handgeschriebene Ziffern zu erkennen. Wenn eine Ziffer, z. B. 5, in verschiedenen Farben geschrieben wurde:

Würde ein streng 2D-CNN eine schlechte Leistung erbringen (da sie zu verschiedenen Kanälen in der z-Dimension gehören)?
Gibt es auch praktische bekannte neuronale Netze, die 3D verwenden Faltung?
Kommentare
- 3D-Faltungen werden häufig für die Verarbeitung von 3D-Bildern wie MRT-Scans verwendet.
- Gibt es Veröffentlichungen? zu 3D Conv-Architekturen?
- @Shobhit Gibt es angesichts der Antwort von ashenoy einen Teil Ihrer Frage, der noch nicht beantwortet wurde?
Antwort
3D-CNNs werden verwendet, wenn Sie Features in 3 Dimensionen extrahieren oder eine Beziehung zwischen 3 Dimensionen herstellen möchten.
Im Wesentlichen ist es dasselbe wie 2D-Faltungen, aber die Kernelbewegung ist jetzt dreidimensional, was eine bessere Erfassung von Abhängigkeiten innerhalb der drei Dimensionen und einen Unterschied in o bewirkt Ausgabedimensionen nach der Faltung.
Der Kernel bei der Faltung bewegt sich in 3 Dimensionen, wenn die Kerntiefe geringer als die Feature-Map-Tiefe ist.
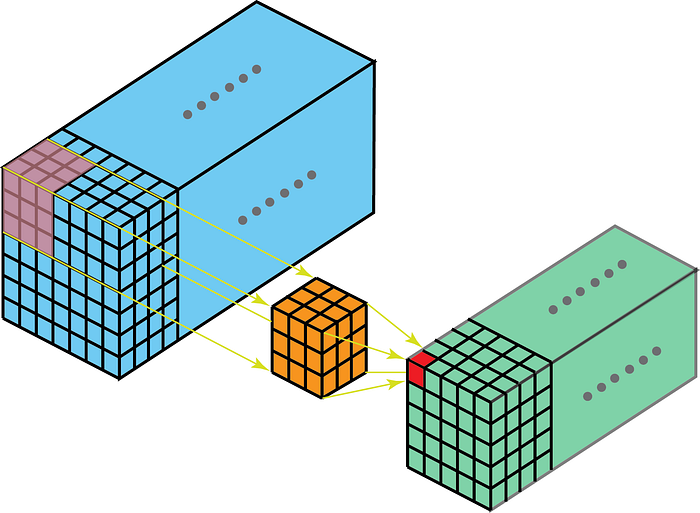
Andererseits bedeuten 2-D-Faltungen bei 3-D-Daten, dass der Kernel nur in 2-D durchläuft. Dies geschieht, wenn die Feature-Map-Tiefe mit der Kernel-Tiefe (Kanäle)
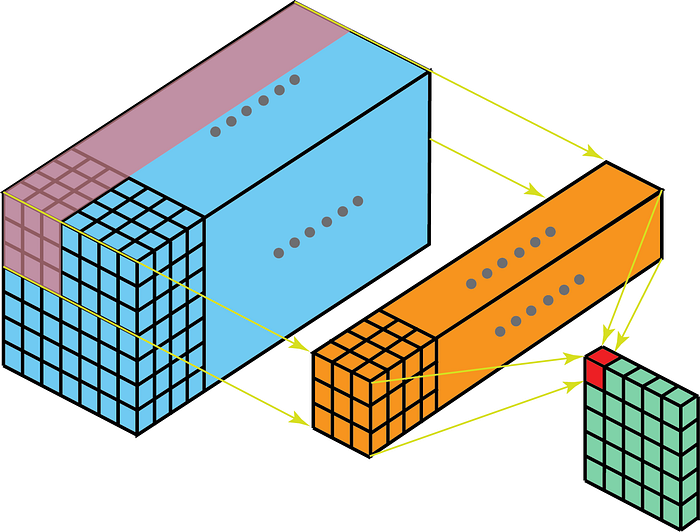
übereinstimmt. Einige Anwendungsfälle dienen dem besseren Verständnis sind – MRT-Scans, bei denen die Beziehung zwischen einem Stapel von Bildern zu verstehen ist; und einen Low-Level-Feature-Extraktor für räumlich-zeitliche Daten wie Videos zur Gestenerkennung, Wettervorhersage usw. (3-D-CNNs werden nur über mehrere kurze Intervalle als Low-Level-Feature-Extraktoren verwendet, da 3D-CNNs langfristig nicht erfassen können räumlich-zeitliche Abhängigkeiten – mehr dazu finden Sie unter ConvLSTM oder einer alternativen Perspektive hier . ) Die meisten CNN-Modelle, die aus Videodaten lernen, haben fast immer 3D-CNN als Low-Level-Feature-Extraktor.
In dem Beispiel, das Sie oben in Bezug auf die Nummer 5 erwähnt haben, würden 2D-Faltungen wahrscheinlich eine bessere Leistung erzielen, da Sie jede Kanalintensität als Aggregat der darin enthaltenen Informationen behandeln, was bedeutet, dass das Lernen fast das ist Das gleiche wie bei einem Schwarzweißbild. Die Verwendung einer 3D-Faltung würde andererseits dazu führen, dass Beziehungen zwischen den Kanälen gelernt werden, die in diesem Fall nicht existieren! (Auch 3D-Faltungen auf einem Bild mit Tiefe 3 würden sehr viel erfordern Gelegentlich verwendeter Kernel, insbesondere für den Anwendungsfall)
Hoffe, Ihre Abfrage wurde gelöscht!
Antwort
3D-Faltungen sollten verwendet werden, wenn Sie räumliche Merkmale aus Ihrer Eingabe in drei Dimensionen extrahieren möchten. Für Computer Vision werden sie normalerweise für volumetrische Bilder , die 3D sind.
Einige Beispiele sind Klassifizierung von gerenderten 3D-Bildern und Segmentierung medizinischer Bilder