컨볼 루션 신경망을 처음 사용하고 3D 컨볼 루션을 배우고 있습니다. 제가 이해할 수있는 것은 2D 컨볼 루션은 XY 차원에서 하위 수준 기능 간의 관계를 제공하는 반면 3D 회선은 모든 3 차원에서 하위 수준 기능과 이들 간의 관계를 감지하는 데 도움이된다는 것입니다.
Consider a 2D 컨벌루션 레이어를 사용하는 CNN은 손으로 쓴 숫자를 인식합니다. 숫자 (예 : 5)가 다른 색상으로 작성된 경우 :

엄격한 2D CNN이 제대로 작동하지 않을까요 (z 차원의 다른 채널에 속하기 때문에)?
또한 3D를 사용하는 잘 알려진 실제 신경망이 있습니까? 컨볼 루션?
댓글
- 3D 컨볼 루션은 MRI 스캔과 같은 3D 이미지 처리에 일반적으로 사용됩니다.
- 출판물이 있습니까? 3D Conv 아키텍처에 대해 알고 계십니까?
- @Shobhit가 ashenoy의 답변을 받았는데 아직 답변되지 않은 질문이 있습니까?
답변
3D CNN “은 3 차원에서 특징을 추출하거나 3 차원 간의 관계를 설정하려는 경우에 사용됩니다.
본질적으로 다음과 같습니다. 2D 컨볼 루션이지만 커널 이동은 이제 3 차원이므로 3 차원 내에서 종속성을 더 잘 포착하고 o 컨볼 루션 후 utput 차원.
커널 깊이가 피쳐 맵 깊이보다 작 으면 컨볼 루션의 커널이 3 차원으로 이동합니다.
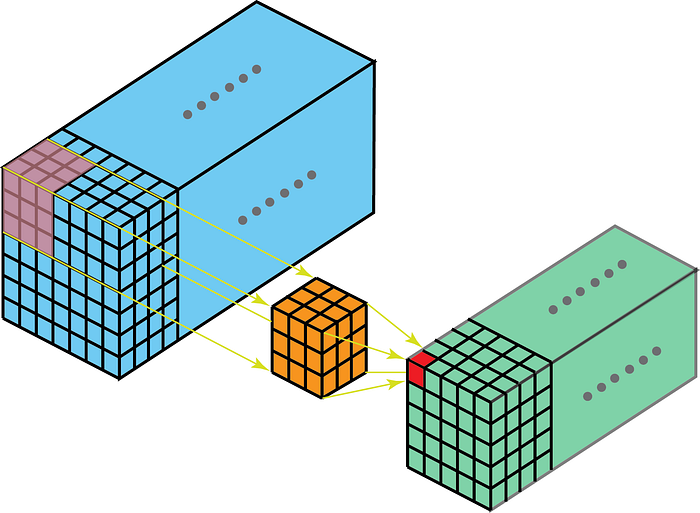
반면에 3 차원 데이터에 대한 2 차원 컨볼 루션은 커널이 2 차원에서만 횡단한다는 것을 의미합니다. 기능 맵 깊이가 커널 깊이 (채널)와 같을 때 발생합니다.
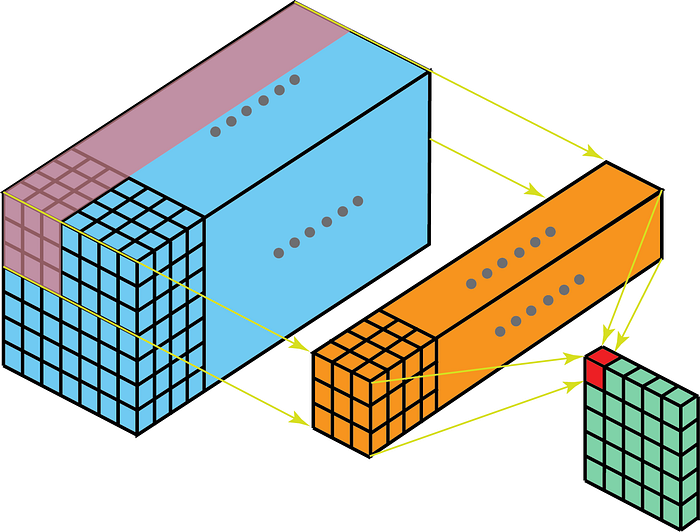
더 나은 이해를위한 일부 사용 사례 -이미지 스택 간의 관계를 이해해야하는 MRI 스캔; 제스처 인식, 날씨 예보 등을위한 비디오와 같은 시공간 데이터를위한 저수준 특징 추출기가 있습니다. (3-D CNN은 3D CNN이 장기간 캡처하지 못하기 때문에 여러 짧은 간격에 걸쳐 저수준 특징 추출기로 사용됩니다. 시공간 종속성- ConvLSTM 또는 여기 에서 대체 관점을 확인하세요. ) 비디오 데이터에서 학습하는 대부분의 CNN 모델은 거의 항상 3D CNN을 저수준 특징 추출기로 사용합니다.
5 번 숫자와 관련하여 위에서 언급 한 예에서 2D 컨볼 루션은 아마도 더 나은 성능을 보일 것입니다. “모든 채널 강도를 보유한 정보의 집합체로 취급하므로 학습은 거의 3D 컨볼 루션을 사용하면이 경우에 존재하지 않는 채널 간의 관계를 학습하게됩니다. (깊이 3 이미지에서 3D 컨볼 루션은 매우 필요합니다. 특히 사용 사례에 사용되는 드문 커널)
쿼리가 삭제 되었기를 바랍니다.
답변
3D 컨볼 루션은 입력에서 공간 특징을 3 차원으로 추출하려는 경우에 사용해야합니다. Computer Vision의 경우 일반적으로 체적 이미지 는 3D입니다.
몇 가지 예는 3D 렌더링 이미지 분류 및 의료 이미지 분할