Sou novo em redes neurais convolucionais e estou aprendendo convolução 3D. O que pude entender é que a convolução 2D nos dá relações entre recursos de baixo nível na dimensão XY, enquanto a convolução 3D ajuda a detectar recursos de baixo nível e relações entre eles em todas as 3 dimensões.
Considere um CNN empregando camadas convolucionais 2D para reconhecer dígitos escritos à mão. Se um dígito, digamos 5, foi escrito em cores diferentes:

Um CNN estritamente 2D teria um desempenho ruim (já que pertencem a canais diferentes na dimensão z)?
Além disso, existem redes neurais bem conhecidas que empregam 3D convolução?
Comentários
- As convoluções 3D são comumente usadas para processar imagens 3D, como varreduras de ressonância magnética.
- Existem publicações nas arquiteturas 3D Conv?
- @Shobhit respondeu ashenoy, alguma parte da sua pergunta ainda não foi respondida?
Resposta
3D CNN “s são usados quando você deseja extrair recursos em 3 dimensões ou estabelecer uma relação entre 3 dimensões.
Basicamente, é o mesmo que Convoluções 2D, mas o movimento do kernel agora é tridimensional, causando uma melhor captura das dependências dentro das 3 dimensões e uma diferença em o dimensões utput pós-convolução.
O kernel na convolução se moverá em 3 dimensões se a profundidade do kernel for menor que a profundidade do mapa de características.
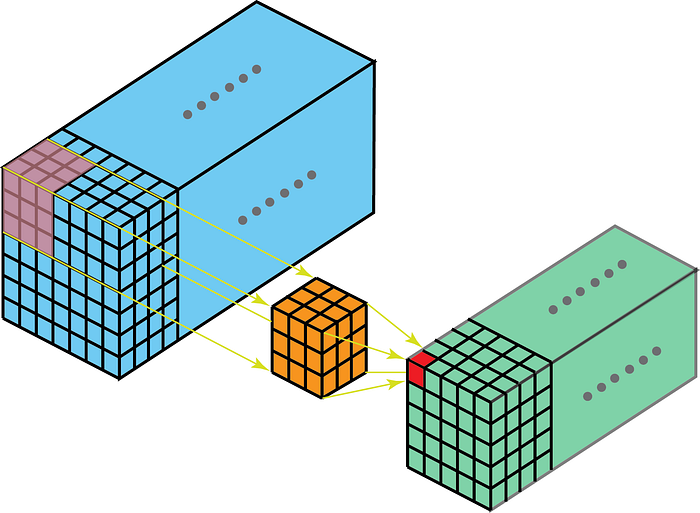
Por outro lado, as convoluções 2-D em dados 3-D significam que o kernel atravessará apenas em 2-D. Isso acontece quando a profundidade do mapa de recursos é igual à profundidade do kernel (canais)
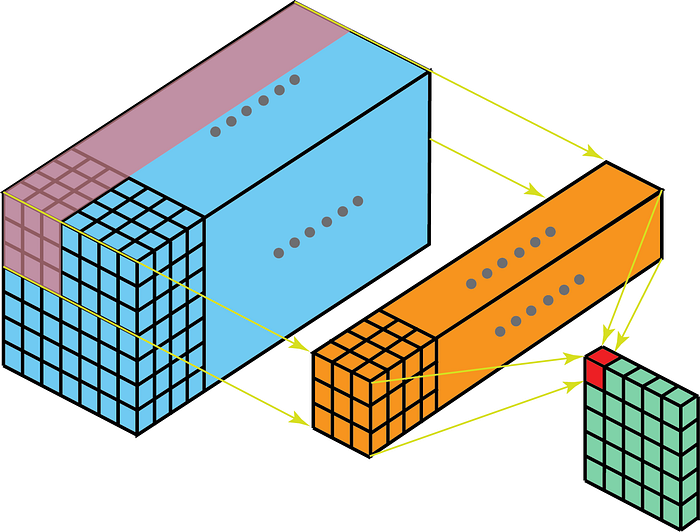
Alguns casos de uso para melhor compreensão são – exames de ressonância magnética em que a relação entre uma pilha de imagens deve ser entendida; e um extrator de recursos de baixo nível para dados espaço-temporais, como vídeos para reconhecimento de gestos, previsão do tempo, etc. (3-D CNNs são usados como extratores de recursos de baixo nível apenas em vários intervalos curtos, pois os 3D CNNs não conseguem capturar a longo prazo dependências espaço-temporais – para mais informações, verifique ConvLSTM ou uma perspectiva alternativa aqui . ) A maioria dos modelos da CNN que aprendem com dados de vídeo quase sempre tem 3D CNN como um extrator de recursos de baixo nível.
No exemplo que você mencionou acima em relação ao número 5 – as convoluções 2D provavelmente teriam um desempenho melhor, já que você está tratando a intensidade de cada canal como um agregado das informações que ele contém, o que significa que o aprendizado seria quase o o mesmo que faria em uma imagem em preto e branco. Usar a convolução 3D para isso, por outro lado, causaria o aprendizado de relações entre os canais que não existem neste caso! (Também as convoluções 3D em uma imagem com profundidade 3 exigiriam um kernel incomum para ser usado, especialmente para o caso de uso)
Espero que sua consulta tenha sido limpa!
Resposta
As convoluções 3D devem quando você deseja extrair características espaciais de sua entrada em três dimensões. Para visão computacional, elas são normalmente usadas em imagens volumétricas , que são 3D.
Alguns exemplos são classificação de imagens renderizadas em 3D e segmentação de imagens médicas