Sunt nou în rețelele neuronale convoluționale și învăț convoluția 3D. Ce aș putea înțelege este că convoluția 2D ne oferă relații între caracteristicile de nivel scăzut din dimensiunea XY, în timp ce convoluția 3D ajută la detectarea caracteristicilor de nivel scăzut și a relațiilor dintre ele în toate cele 3 dimensiuni.
Luați în considerare o CNN folosește straturi convoluționale 2D pentru a recunoaște cifrele scrise de mână. Dacă o cifră, să zicem 5, a fost scrisă în culori diferite:

O CNN strict 2D ar funcționa slab (deoarece aparțin unor canale diferite din dimensiunea z)?
De asemenea, există rețele neuronale practice bine cunoscute care folosesc 3D convoluție?
Comentarii
- Convoluțiile 3D sunt utilizate în mod obișnuit pentru procesarea imaginilor 3D, cum ar fi scanările RMN.
- Există publicații pe arhitecturi 3D Conv?
- @Shobhit a primit răspunsul lui ashenoy, există o parte din întrebarea dvs. care nu a primit încă răspuns?
Răspuns
3D CNN „sunt utilizate atunci când doriți să extrageți caracteristici în 3 dimensiuni sau să stabiliți o relație între 3 dimensiuni.
În esență, este la fel ca Convoluții 2D, dar mișcarea nucleului este acum tridimensională, provocând o mai bună captare a dependențelor în cele 3 dimensiuni și o diferență în o utput dimensions post convolution.
Kernel-ul pe convolution se va deplasa în 3-Dimensions dacă adâncimea nucleului este mai mică decât adâncimea hărții caracteristicilor.
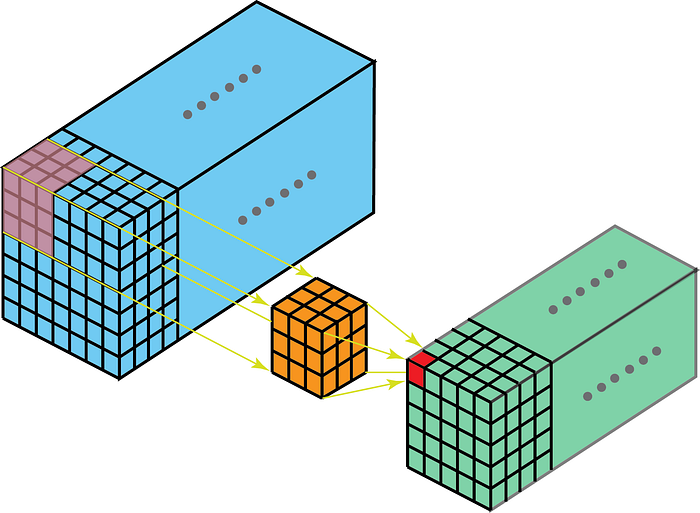
Pe de altă parte, convoluțiile 2-D pe datele 3-D înseamnă că nucleul va traversa numai în 2-D. Acest lucru se întâmplă atunci când adâncimea hărții caracteristicilor este aceeași cu adâncimea nucleului (canale)
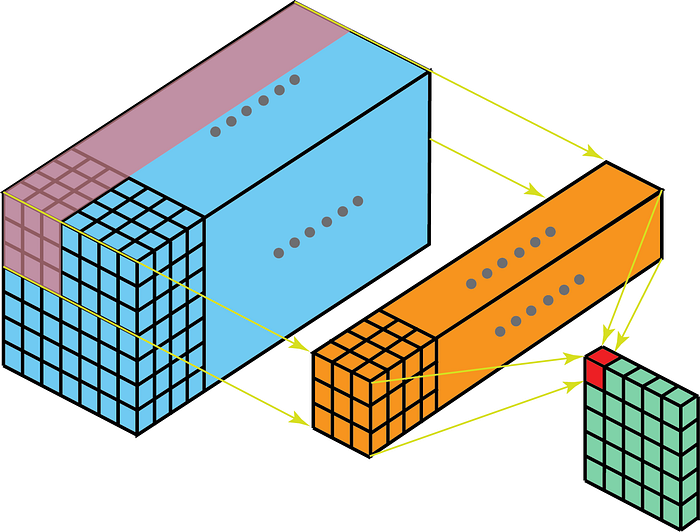
Unele cazuri de utilizare pentru o mai bună înțelegere sunt – scanări RMN în care trebuie înțeleasă relația dintre un teanc de imagini; și un extractor de caracteristici de nivel scăzut pentru date spațio-temporale, cum ar fi videoclipuri pentru recunoașterea gesturilor, prognoză meteo etc. (CNN 3-D sunt utilizate ca extractoare de caracteristici de nivel scăzut doar pe intervale scurte multiple, deoarece CNN 3D nu reușește să capteze pe termen lung dependențe spațio-temporale – pentru mai multe detalii, consultați ConvLSTM sau o perspectivă alternativă aici . ) Majoritatea modelelor CNN care învață din datele video au aproape întotdeauna 3D CNN ca un extractor de caracteristici de nivel scăzut.
În exemplul pe care l-ați menționat mai sus cu privire la numărul 5 – 2D convoluțiile ar funcționa probabil mai bine, deoarece tratați intensitatea fiecărui canal ca un agregat al informațiilor pe care le deține, ceea ce înseamnă că învățarea ar fi aproape la fel ca pe o imagine alb-negru. Folosirea convoluției 3D pentru aceasta, pe de altă parte, ar determina învățarea relațiilor dintre canale care nu există în acest caz! (De asemenea, convoluțiile 3D pe o imagine cu adâncimea 3 ar necesita o foarte mare kernel neobișnuit de utilizat, în special pentru cazul de utilizare)
Sper că interogarea dvs. a fost ștearsă!
Răspundeți
Convoluțiile 3D ar trebui atunci când doriți să extrageți caracteristici spațiale din intrarea dvs. pe trei dimensiuni. Pentru Computer Vision, acestea sunt de obicei utilizate pe imagini volumetrice , care sunt 3D.
Unele exemple sunt clasificarea imaginilor redate 3D și segmentarea imaginii medicale