Jag är ny i favörliga neurala nätverk och jag lär mig 3D-faltning. Vad jag kunde förstå är att 2D-faltning ger oss förhållanden mellan funktioner på låg nivå i XY-dimensionen, medan 3D-faltning hjälper till att upptäcka funktioner på låg nivå och förhållanden mellan dem i alla de 3 dimensionerna.
Tänk på en CNN som använder 2D-fällningsskikt för att känna igen handskrivna siffror. Om en siffra, säg 5, skrevs i olika färger:

Skulle ett strikt 2D CNN prestera dåligt (eftersom de tillhör olika kanaler i z-dimensionen)?
Finns det också praktiska välkända neurala nät som använder 3D konvolution?
Kommentarer
- 3D-viklingar används ofta för att bearbeta 3D-bilder som MR-skanningar.
- Finns det några publikationer om 3D Conv-arkitekturer?
- @Shobhit ges svaret av ashenoy, finns det någon del av din fråga som inte har besvarats än?
Svar
3D CNN ”används när du vill extrahera funktioner i 3 dimensioner eller skapa en relation mellan 3 dimensioner.
I huvudsak är det samma som 2D-krökningar men kärnrörelsen är nu tredimensionell vilket orsakar en bättre fångst av beroenden inom de 3 dimensionerna och en skillnad i o utmatningsdimensioner efter fällning.
Kärnan vid faltning rör sig i 3-dimensioner om kärndjupet är mindre än funktionskartdjupet.
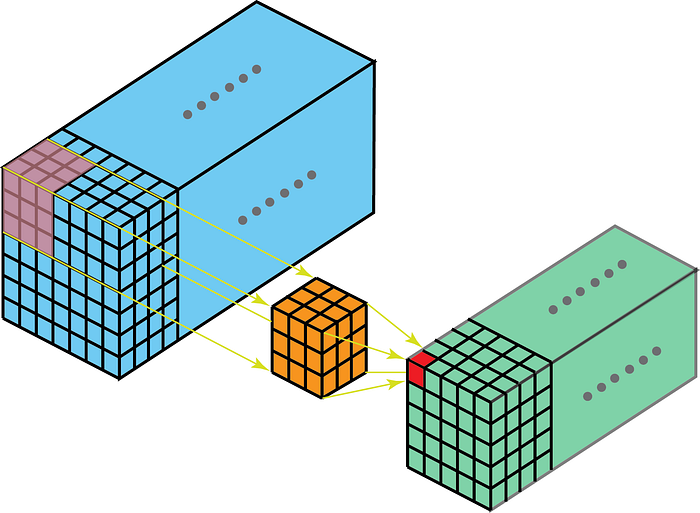
Å andra sidan betyder 2-D-krökningar på 3-D-data att kärnan endast kommer att korsa i 2-D. Detta händer när funktionskartdjupet är detsamma som kärndjupet (kanaler)
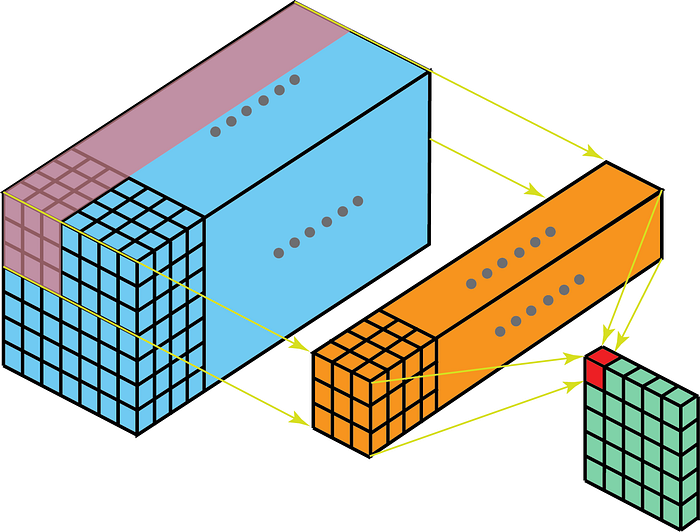
Vissa använder fall för bättre förståelse är – MR-skanningar där förhållandet mellan en bildstapel ska förstås; och en lågnivåfunktionsutdragare för rumstemporal data som videoklipp för gestigenkänning, väderprognos etc. (3-D CNN används endast som extraktorer med låg nivå med flera korta intervall eftersom 3D CNN inte lyckas fånga långsiktigt rumsliga och tidsmässiga beroenden – för mer om det, kolla in ConvLSTM eller ett alternativt perspektiv här . ) De flesta CNN-modeller som lär sig av videodata har nästan alltid 3D CNN som en lågnivåfunktionsutdragare.
I exemplet du har nämnt ovan beträffande antalet 5 – 2D-förvirringar skulle förmodligen fungera bättre, eftersom du behandlar varje kanalintensitet som en sammanställning av den information den innehåller, vilket innebär att inlärningen nästan är samma som det skulle på en svartvit bild. Att använda 3D-faltning för detta å andra sidan skulle orsaka inlärning av relationer mellan kanalerna som inte finns i det här fallet! (Även 3D-krökningar på en bild med djup 3 skulle kräva en mycket ovanlig kärna som ska användas, särskilt för användningsfallet)
Hoppas att din fråga har rensats!
Svar
3D-kretsar bör när du vill extrahera rumsfunktioner från din inmatning i tre dimensioner. För datorvision används de vanligtvis på volymetriska bilder , som är 3D.
Några exempel är klassificerar 3D-renderade bilder och medicinsk bildsegmentering