Jeg er ny inden for nedbrydning af neurale netværk, og jeg lærer 3D-sammenfald. Det, jeg kunne forstå, er, at 2D-foldning giver os forhold mellem lavt niveau-funktioner i XY-dimensionen, mens 3D-foldning hjælper med at opdage funktioner på lavt niveau og forhold mellem dem i alle de 3 dimensioner.
Overvej en CNN, der anvender 2D-konvolutionslag til at genkende håndskrevne cifre. Hvis et ciffer, for eksempel 5, blev skrevet i forskellige farver:

Ville en strengt 2D CNN klarer sig dårligt (da de tilhører forskellige kanaler i z-dimensionen)?
Er der også praktiske velkendte neurale net, der anvender 3D foldning?
Kommentarer
- 3D-konvolveringer bruges ofte til behandling af 3D-billeder såsom MR-scanninger.
- Er der nogen publikationer om 3D Conv-arkitekturer?
- @Shobhit givet svaret af ashenoy, er der en del af dit spørgsmål, der endnu ikke er blevet besvaret?
Svar
3D CNNer bruges, når du vil udtrække funktioner i 3 dimensioner eller etablere en sammenhæng mellem 3 dimensioner.
Det er i det væsentlige det samme som 2D-indviklinger, men kernebevægelsen er nu tredimensionel, hvilket forårsager en bedre indfangning af afhængigheder inden for de 3 dimensioner og en forskel i o udgangsdimensioner efter konvolution.
Kernen på konvolution bevæger sig i 3-dimensioner, hvis kernedybden er mindre end funktionskortets dybde.
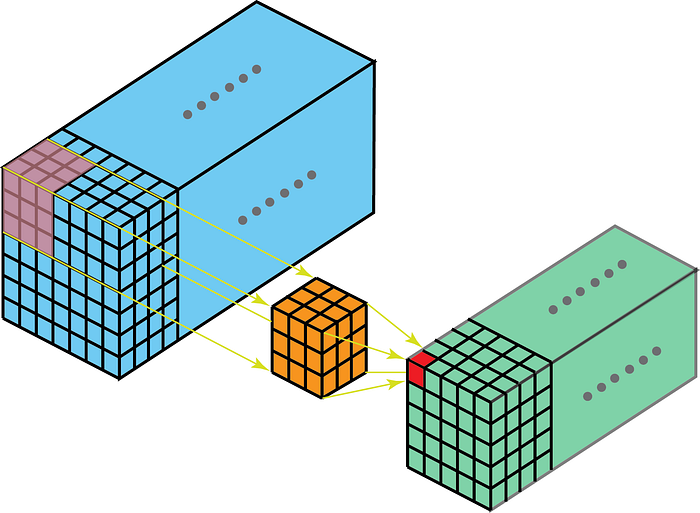
På den anden side betyder 2-D-indviklinger på 3-D-data, at kernen kun krydser i 2-D. Dette sker, når funktionskortdybden er den samme som kernedybden (kanaler)
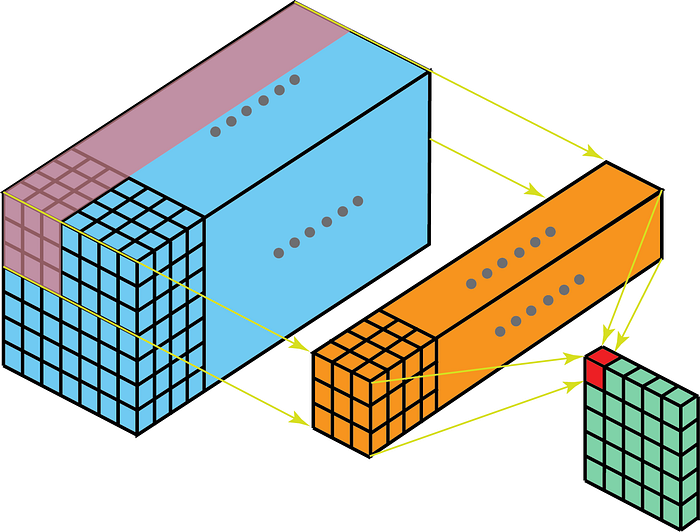
Nogle bruger sager for bedre forståelse are – MR-scanninger, hvor forholdet mellem en stak billeder skal forstås; og et lavt niveau-ekstraktor til rumtemporale data som videoer til Gesture Recognition, Vejrudsigt osv. (3-D CNNer bruges kun som ekstrakonstruktioner med lavt niveau over flere korte intervaller, da 3D CNNer ikke fanger langvarig spatio-temporale afhængigheder – for mere om det, se ConvLSTM eller et alternativt perspektiv her . ) De fleste CNN-modeller, der lærer af videodata, har næsten altid 3D CNN som en ekstraktor med lavt niveau.
I eksemplet, du har nævnt ovenfor, angående antallet 5 – 2D-konvolveringer ville sandsynligvis fungere bedre, da du behandler hver kanalintensitet som et samlet af den information, det indeholder, hvilket betyder, at læringen næsten vil være den det samme som på et sort / hvidt billede. Brug af 3D-sammenblanding til dette på den anden side ville medføre læring af forholdet mellem kanalerne, som ikke findes i dette tilfælde! (Også 3D-viklinger på et billede med dybde 3 ville kræve en meget ualmindelig kerne, der skal bruges, især til brugssagen)
Håber din forespørgsel er ryddet!
Svar
3D-indviklinger skal, når du ønsker at udtrække rumlige funktioner fra din input i tre dimensioner. For Computer Vision bruges de typisk på volumetriske billeder , som er 3D.
Nogle eksempler er klassificering af 3D-gengivne billeder og medicinsk billedsegmentering