Olen uusi konvoluutiohermoverkoissa ja opettelen 3D-konvoluutiota. Ymmärrän, että 2D-konvoluutio antaa meille suhdetta matalan tason ominaisuuksien välillä XY-ulottuvuudessa, kun taas 3D-konvoluutio auttaa havaitsemaan matalan tason ominaisuuksia ja niiden välisiä suhteita kaikissa kolmessa ulottuvuudessa.
Harkitse CNN, joka käyttää 2D-konvoluutiokerroksia käsinkirjoitettujen numeroiden tunnistamiseen. Jos luku, sanotaan 5, kirjoitettiin eri väreillä:

Suorittaisiko tiukasti 2D-CNN huonosti (koska ne kuuluvat z-ulottuvuuden eri kanaviin)?
Onko myös käytännöllisiä tunnettuja hermoverkkoja, jotka käyttävät 3D: tä konvoluutio?
Kommentit
- 3D-käänteitä käytetään yleisesti 3D-kuvien, kuten MRI-skannausten, käsittelyyn.
- Onko julkaisuja 3D Conv -arkkitehtuureista?
- @Shobhit antoi ashenoy vastauksen, onko kysymyksessäsi vielä jotain vastausta?
Vastaus
3D CNN: itä käytetään, kun haluat purkaa 3 ulottuvuuden ominaisuuksia tai luoda suhde 3 ulottuvuuden välille.
Pohjimmiltaan sama kuin 2D-konvoluutiot, mutta ytimen liike on nyt kolmiulotteinen aiheuttaen paremman riippuvuuksien vangitsemisen 3 ulottuvuudessa ja eron o utput-mittasuhteet konvoluution jälkeen.
Konvoluution ydin liikkuu kolmiulotteisina, jos ytimen syvyys on pienempi kuin karttakohteen syvyys.
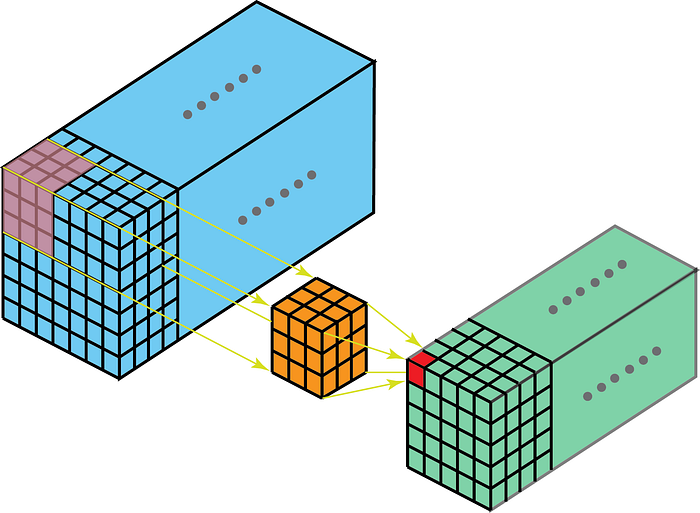
Toisaalta 3D-datan 2-D-kääntymät tarkoittavat, että ydin kulkee vain 2-D-muodossa. Näin tapahtuu, kun karttakartan syvyys on sama kuin ytimen syvyys (kanavat)
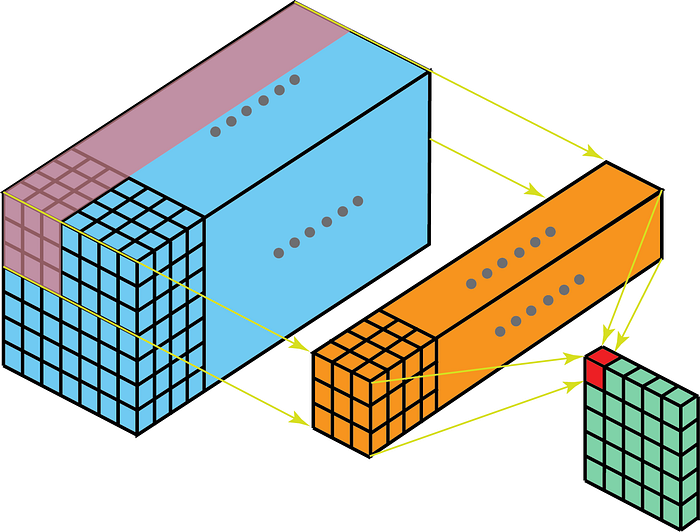
Jotkut käyttötapaukset ymmärtämisen parantamiseksi ovat – MRI-skannaus, jossa kuvapinon suhde on ymmärrettävä; ja matalan tason ominaisuuserotin ajallista tilatietoa varten, kuten videot eleentunnistusta, sääennustetta jne. varten (3D-CNN: itä käytetään matalan tason ominaisuuserotimina vain useilla lyhyillä aikaväleillä, koska 3D CNN ei pysty kaappaamaan pitkällä aikavälillä aika-ajalliset riippuvuudet – saat lisätietoja siitä ConvLSTM tai vaihtoehtoisen perspektiivin täällä . ) Useimmissa videotiedoista oppivissa CNN-malleissa 3D-CNN on melkein aina matalatasoinen ominaisuuserotin.
Edellä mainitsemassasi esimerkissä luvusta 5 – 2D-konvoluutiot toimisivat todennäköisesti paremmin, kun käsittelet jokaista kanavan voimakkuutta sen sisältämän tiedon kokonaisuutena, mikä tarkoittaa, että oppiminen olisi melkein sama kuin mustavalkoisella kuvalla. 3D-konvoluution käyttäminen tähän toisaalta aiheuttaisi suhteiden oppimisen kanavien välillä, joita tässä tapauksessa ei ole! (Myös 3D-konvoluutiot kuvassa, jonka syvyys on 3, vaativat hyvin epätavallinen ydin, erityisesti käyttötapauksessa)
Toivottavasti kyselysi on tyhjennetty!
Vastaa
3D-kokoonpanojen tulisi olla, kun haluat poimia paikkatietoja syötteestäsi kolmella ulottuvuudella. Computer Vision -ohjelmassa niitä käytetään tyypillisesti tilavuuskuvissa , jotka ovat kolmiulotteisia.
Joitakin esimerkkejä ovat 3D-renderoitujen kuvien luokittelu ja lääketieteellisen kuvan segmentointi