Je suis nouveau dans les réseaux de neurones convolutifs et japprends la convolution 3D. Ce que je pourrais comprendre, cest que la convolution 2D nous donne des relations entre les entités de bas niveau dans la dimension XY, tandis que la convolution 3D aide à détecter les entités de bas niveau et les relations entre elles dans les 3 dimensions.
Considérez une CNN utilisant des couches convolutives 2D pour reconnaître les chiffres manuscrits. Si un chiffre, disons 5, a été écrit dans des couleurs différentes:

Un CNN strictement 2D fonctionnerait-il mal (car ils appartiennent à différents canaux dans la dimension z)?
En outre, existe-t-il des réseaux de neurones pratiques bien connus qui utilisent la 3D convolution?
Commentaires
- Les convolutions 3D sont couramment utilisées pour le traitement dimages 3D telles que les IRM.
- Existe-t-il des publications sur les architectures 3D Conv?
- @Shobhit étant donné la réponse dAshenoy, y a-t-il une partie de votre question qui na pas encore reçu de réponse?
Réponse
Les CNN 3D sont utilisés lorsque vous souhaitez extraire des entités en 3 dimensions ou établir une relation entre 3 dimensions.
Cest essentiellement la même chose que Convolutions 2D mais le mouvement du noyau est maintenant en 3 dimensions, ce qui entraîne une meilleure capture des dépendances dans les 3 dimensions et une différence en o utput dimensions post convolution.
Le noyau sur convolution se déplacera en 3 dimensions si la profondeur du noyau est inférieure à la profondeur de la carte des caractéristiques.
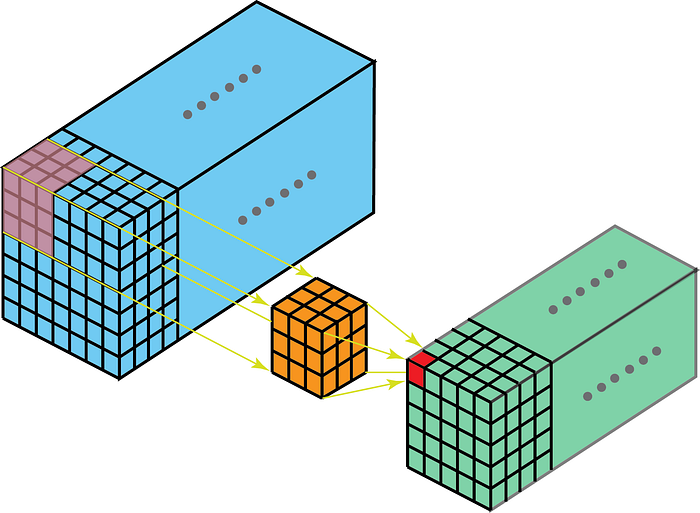
Dautre part, les convolutions 2D sur des données 3D signifient que le noyau ne traversera quen 2D. Cela se produit lorsque la profondeur de la carte des caractéristiques est la même que la profondeur du noyau (canaux)
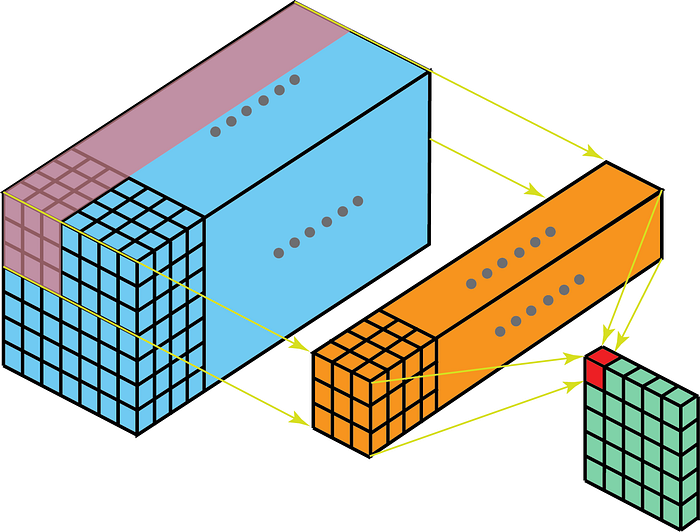
Quelques cas dutilisation pour une meilleure compréhension are – IRM où la relation entre une pile dimages doit être comprise; et un extracteur de fonctionnalités de bas niveau pour les données spatio-temporelles telles que les vidéos pour la reconnaissance gestuelle, les prévisions météorologiques, etc. (les CNN 3D sont utilisés comme extracteurs de fonctionnalités de bas niveau uniquement sur plusieurs intervalles courts car les CNN 3D ne parviennent pas à capturer à long terme Dépendances spatio-temporelles – pour en savoir plus, consultez ConvLSTM ou une autre perspective ici . ) La plupart des modèles CNN qui apprennent à partir de données vidéo ont presque toujours CNN 3D comme extracteur de fonctionnalités de bas niveau.
Dans lexemple que vous avez mentionné ci-dessus concernant le nombre 5 – les convolutions 2D seraient probablement plus performantes, car vous « traitez chaque intensité de canal comme un agrégat des informations quelle contient, ce qui signifie que lapprentissage serait presque le comme il le ferait sur une image en noir et blanc. Lutilisation de la convolution 3D pour cela entraînerait par contre lapprentissage de relations entre les canaux qui nexistent pas dans ce cas! (Aussi les convolutions 3D sur une image de profondeur 3 nécessiteraient une très noyau inhabituel à utiliser, en particulier pour le cas dutilisation)
Jespère que votre requête a été effacée!
Réponse
Les convolutions 3D doivent être utilisées lorsque vous souhaitez extraire des entités spatiales de votre entrée sur trois dimensions. Pour la vision par ordinateur, elles sont généralement utilisées sur images volumétriques , qui sont en 3D.
Quelques exemples sont classifiant les images rendues en 3D et segmentation des images médicales