Jeg er ny i konvolusjonelle nevrale nettverk, og jeg lærer 3D-konvolusjon. Det jeg kunne forstå er at 2D-konvolusjon gir oss forhold mellom lavt nivåfunksjoner i XY-dimensjonen, mens 3D-konvolusjon hjelper med å oppdage funksjoner på lavt nivå og forholdet mellom dem i alle de 3 dimensjonene.
Tenk på CNN som bruker 2D-konvolusjonslag for å gjenkjenne håndskrevne sifre. Hvis et siffer, si 5, ble skrevet i forskjellige farger:

Ville en strengt 2D CNN prestere dårlig (siden de tilhører forskjellige kanaler i z-dimensjonen)?
Er det også praktiske velkjente nevrale nett som benytter 3D konvolusjon?
Kommentarer
- 3D-konvolusjoner brukes ofte til behandling av 3D-bilder som MR-skanning.
- Er det noen publikasjoner på 3D Conv-arkitekturer?
- @Shobhit gitt svaret av ashenoy, er det noe av spørsmålet ditt som ikke har blitt besvart ennå?
Svar
3D CNN «brukes når du vil trekke ut funksjoner i 3 dimensjoner eller etablere en sammenheng mellom 3 dimensjoner.
Det er i hovedsak det samme som 2D-forviklinger, men kjernebevegelsen er nå tredimensjonal og forårsaker bedre fangst av avhengigheter innenfor de tre dimensjonene og en forskjell i o utdata dimensjoner etter konvolusjon.
Kjernen ved konvolusjon vil bevege seg i 3-dimensjoner hvis kjernedybden er mindre enn funksjonskartdybden.
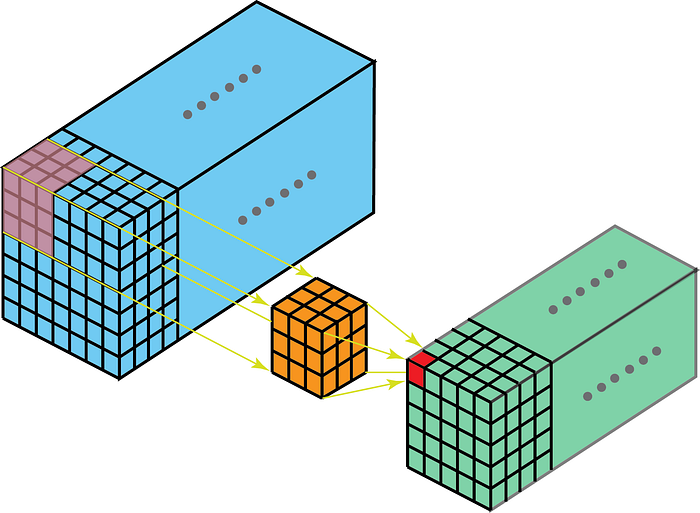
På den annen side betyr 2-D-viklinger på 3-D-data at kjernen bare vil krysse i 2-D. Dette skjer når funksjonskartdybden er den samme som kjernedybden (kanaler)
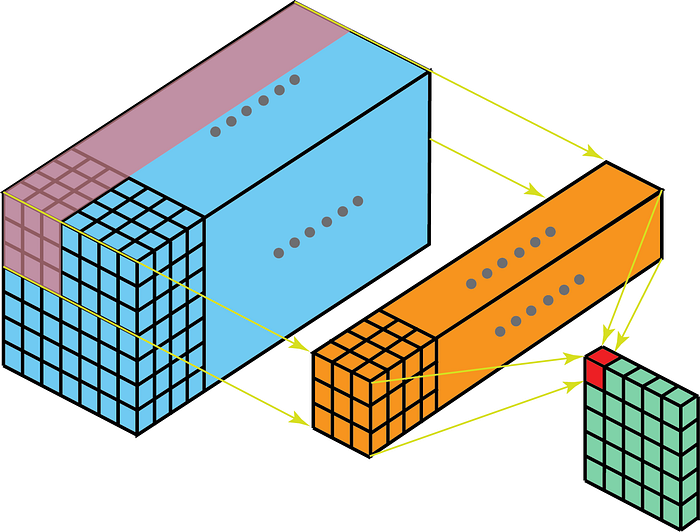
Noen bruker saker for bedre forståelse are – MR-skanninger der forholdet mellom en bunke med bilder skal forstås; og en lavt funksjonsavtrekker for romtemporale data som videoer for bevegelsesgjenkjenning, værmelding osv. (3-D CNN-er brukes som funksjonstrekkere på lavt nivå bare over flere korte intervaller, da 3D CNN ikke klarer å fange langsiktig romlige-tidsmessige avhengigheter – for mer om det, sjekk ut ConvLSTM eller et alternativt perspektiv her . ) De fleste CNN-modeller som lærer av videodata, har nesten alltid 3D CNN som en ekstraktor med lavt nivå.
I eksemplet du har nevnt ovenfor angående antall 5 – 2D-konvolusjoner ville trolig fungere bedre, ettersom du behandler hver kanalintensitet som en samlet del av informasjonen den inneholder, noe som betyr at læringen nesten vil være den det samme som på et svart-hvitt bilde. Bruk av 3D-konvolusjon til dette på den annen side vil føre til læring av forhold mellom kanalene som ikke eksisterer i dette tilfellet! (Også 3D-kronglinger på et bilde med dybde 3 vil kreve en veldig uvanlig kjerne som skal brukes, spesielt for brukstilfellet)
Håper søket ditt er ryddet!
Svar
3D-konvolusjoner bør være når du vil trekke ut romlige funksjoner fra innspillene dine i tre dimensjoner. For Computer Vision brukes de vanligvis på volumetriske bilder , som er 3D.
Noen eksempler er klassifisering av 3D-gjengitte bilder og medisinsk bildesegmentering