Ik ben nieuw in convolutionele neurale netwerken, en ik leer 3D convolutie. Wat ik kon begrijpen, is dat 2D-convolutie ons relaties geeft tussen low-level features in de XY-dimensie, terwijl de 3D-convolutie low-level features en relaties daartussen helpt detecteren in alle 3 dimensies.
Overweeg een CNN gebruikt 2D convolutionele lagen om handgeschreven cijfers te herkennen. Als een cijfer, bijvoorbeeld 5, in verschillende kleuren is geschreven:

Zou een strikt 2D CNN slecht presteren (aangezien ze tot verschillende kanalen in de z-dimensie behoren)?
Zijn er ook praktische bekende neurale netwerken die 3D convolutie?
Opmerkingen
- 3D-convoluties worden vaak gebruikt voor het verwerken van 3D-afbeeldingen zoals MRI-scans.
- Zijn er publicaties op 3D Conv-architecturen?
- @Shobhit gegeven het antwoord van ashenoy, is er een deel van uw vraag dat nog niet is beantwoord?
Antwoord
3D CNN “s worden gebruikt wanneer u objecten wilt extraheren in 3 dimensies of een relatie wilt leggen tussen 3 dimensies.
In wezen is het hetzelfde als 2D-convoluties maar de kernelbeweging is nu 3-dimensionaal, wat een betere opname van afhankelijkheden binnen de 3 dimensies en een verschil in o utput dimensies na convolutie.
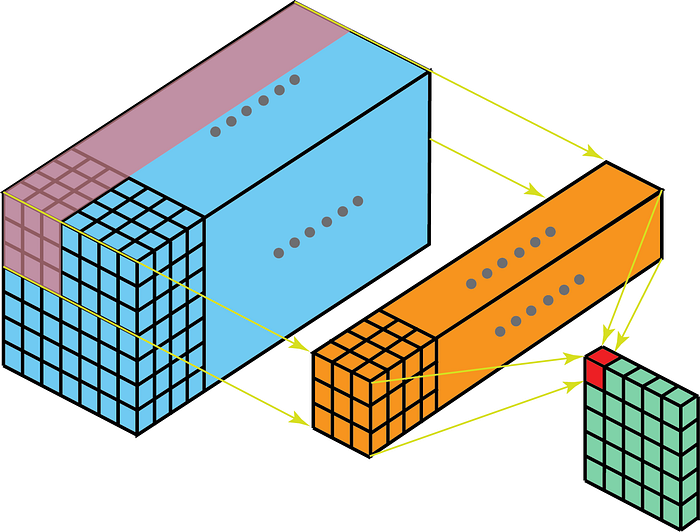
De kernel op convolutie zal in 3-Dimensions bewegen als de kerneldiepte kleiner is dan de feature map diepte.
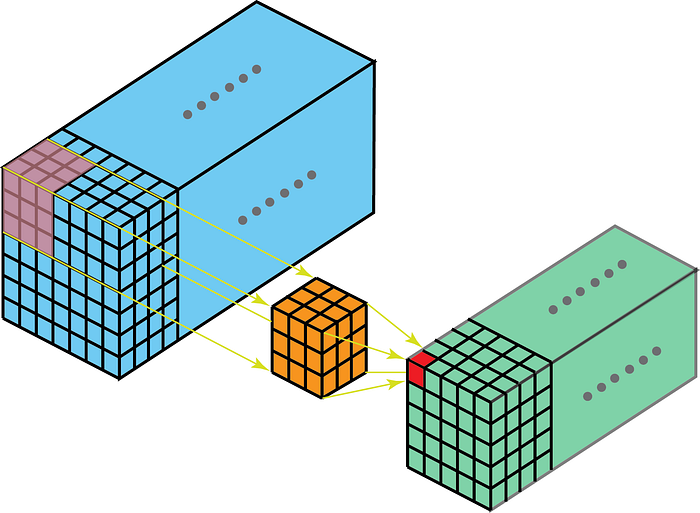
Aan de andere kant betekenen 2D-convoluties op 3D-gegevens dat de kernel alleen in 2D zal doorkruisen. Dit gebeurt wanneer de diepte van de feature map hetzelfde is als de diepte van de kernel (kanalen)
Enkele use cases voor een beter begrip zijn – MRI-scans waarbij de relatie tussen een stapel afbeeldingen moet worden begrepen; en een functie-extractor op laag niveau voor spatio-temporele gegevens zoals videos voor gebarenherkenning, weersvoorspelling enz. (3D CNNs worden alleen gebruikt als extraheren op laag niveau voor meerdere korte intervallen, omdat 3D CNNs er niet in slagen om lange termijn vast te leggen spatio-temporele afhankelijkheden – voor meer daarover ga je naar ConvLSTM of een alternatief perspectief hier . ) De meeste CNN-modellen die leren van videogegevens hebben bijna altijd 3D CNN als een functie-extractor op laag niveau.
In het voorbeeld dat je hierboven hebt genoemd met betrekking tot het aantal 5 – 2D-convoluties zouden waarschijnlijk beter presteren, aangezien je “elke kanaalintensiteit opnieuw behandelt als een verzameling van de informatie die het bevat, wat betekent dat het leren bijna de hetzelfde als op een zwart-witafbeelding. Als u hiervoor 3D-convolutie gebruikt, zou dit er echter toe leiden dat relaties tussen de kanalen worden ontdekt die in dit geval niet bestaan! (Ook voor 3D-convoluties op een afbeelding met diepte 3 zou een zeer ongebruikelijke kernel om te gebruiken, vooral voor het gebruik)
Ik hoop dat je vraag is gewist!
Antwoord
3D-convoluties zouden moeten zijn wanneer u ruimtelijke kenmerken wilt extraheren uit uw invoer op drie dimensies. Voor Computer Vision worden ze meestal gebruikt op volumetrische afbeeldingen , die 3D zijn.
Enkele voorbeelden zijn classificeren van 3D-gerenderde afbeeldingen en segmentatie van medische afbeeldingen