Nie mam doświadczenia w konwolucyjnych sieciach neuronowych i uczę się splotu 3D. Mogłem zrozumieć, że splot 2D daje nam relacje między cechami niskiego poziomu w wymiarze XY, podczas gdy splot 3D pomaga wykryć cechy niskiego poziomu i relacje między nimi we wszystkich 3 wymiarach.
Rozważmy CNN wykorzystuje warstwy splotowe 2D do rozpoznawania odręcznych cyfr. Jeśli cyfra, powiedzmy 5, została zapisana w różnych kolorach:

Czy stricte 2D CNN działałyby słabo (ponieważ należą do różnych kanałów w wymiarze z)?
Czy istnieją również dobrze znane praktyczne sieci neuronowe, które wykorzystują 3D splot?
Komentarze
- Konwencje 3D są powszechnie używane do przetwarzania obrazów 3D, takich jak skany MRI.
- Czy są jakieś publikacje na architekturach 3D Conv?
- @Shobhit otrzymał odpowiedź od ashenoy, czy jest jakaś część Twojego pytania, na którą jeszcze nie ma odpowiedzi?
Odpowiedź
3D CNN „są używane, gdy chcesz wyodrębnić elementy w 3 wymiarach lub ustalić związek między 3 wymiarami.
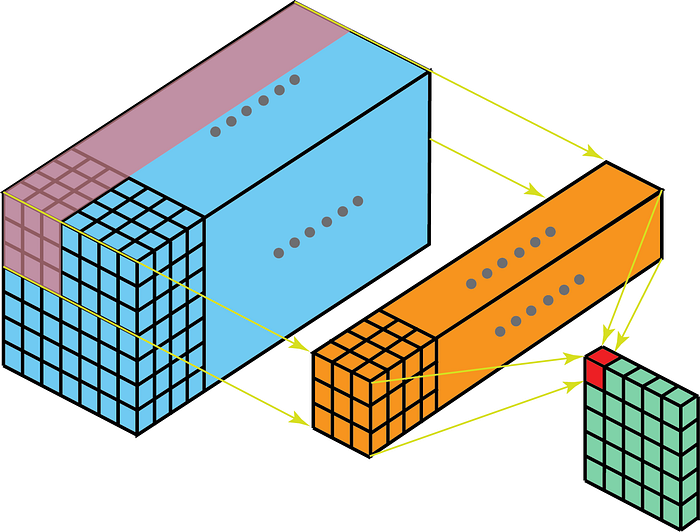
Zasadniczo jest taki sam jak Zwoje 2D, ale ruch jądra jest teraz trójwymiarowy, co powoduje lepsze uchwycenie zależności w 3 wymiarach i różnicę w o wymiary utput po splataniu.
Jądro na splotach przesunie się w 3-wymiarach, jeśli głębokość jądra jest mniejsza niż głębokość mapy funkcji.
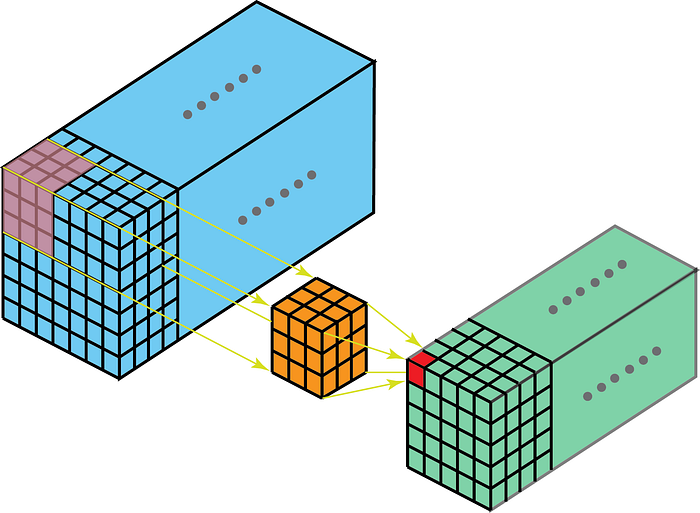
Z drugiej strony zwoje dwuwymiarowe na danych trójwymiarowych oznaczają, że jądro będzie przechodzić tylko w dwuwymiarowym. Dzieje się tak, gdy głębokość mapy obiektów jest taka sama jak głębokość jądra (kanały)
Niektóre przypadki użycia dla lepszego zrozumienia are – skany MRI, w których należy zrozumieć związek między stosem obrazów; i niskopoziomowy ekstraktor funkcji do danych czasowo-przestrzennych, takich jak filmy do rozpoznawania gestów, prognozy pogody itp. (3-D CNN są używane jako ekstraktory funkcji niskiego poziomu tylko w wielu krótkich odstępach czasu, ponieważ 3D CNN nie przechwytuje długoterminowych zależności czasowo-przestrzenne – więcej informacji na ten temat znajdziesz ConvLSTM lub alternatywną perspektywę tutaj . Większość modeli CNN uczących się na podstawie danych wideo prawie zawsze ma 3D CNN jako ekstraktor funkcji niskiego poziomu.
W przykładzie, o którym wspomniałeś powyżej, dotyczącym liczby 5 – zwoje 2D prawdopodobnie działałyby lepiej, ponieważ „traktujesz intensywność każdego kanału jako sumę informacji, które zawiera, co oznacza, że nauka byłaby prawie tak samo jak na obrazie czarno-białym. Z drugiej strony, użycie splotu 3D do tego celu spowodowałoby uczenie się relacji między kanałami, które w tym przypadku nie istnieją! (Również konwolucje 3D na obrazie o głębi 3 wymagałyby bardzo nietypowe jądro do użycia, szczególnie w przypadku użycia)
Mam nadzieję, że twoje zapytanie zostało wyczyszczone!
Odpowiedź
Zwinięcia 3D powinny być przydatne, gdy chcesz wyodrębnić elementy przestrzenne z wprowadzonych danych w trzech wymiarach. W przypadku widzenia komputerowego są one zwykle używane na obrazach objętościowych , które są trójwymiarowe.
Niektóre przykłady to klasyfikowanie renderowanych obrazów 3D i segmentacja obrazów medycznych