Új vagyok a konvolúciós neurális hálózatokban, és megtanulom a 3D konvolúciót. Megértettem, hogy a 2D konvolúció kapcsolatokat ad az XY dimenzió alacsony szintű jellemzői között, míg a 3D konvolúció mind a 3 dimenzióban segít észlelni az alacsony szintű jellemzőket és a köztük lévő kapcsolatokat.
Vegyünk egy A CNN 2D konvolúciós rétegeket alkalmaz a kézírásos számjegyek felismerésére. Ha egy számjegyet, mondjuk 5-öt, különböző színekkel írtak:

A szigorúan 2D-s CNN gyengén teljesítene (mivel a z-dimenzióban különböző csatornákhoz tartoznak)?
Továbbá léteznek olyan praktikus, jól ismert ideghálók, amelyek 3D-t alkalmaznak konvolúció?
Megjegyzések
- A 3D-s konvolúciókat általában 3D-s képek, például MRI-vizsgálatok feldolgozására használják.
- Van-e publikáció a 3D Conv architektúrákon?
- @Shobhit megadta a választ ashenoy, van-e olyan része a kérdésének, amelyre még nem érkezett válasz?
Válasz
A 3D CNN-ek akkor használatosak, ha 3 dimenzióban szeretne kibontani funkciókat, vagy kapcsolatot szeretne létrehozni 3 dimenzió között.
Lényegében ugyanaz, mint a 2D konvolúciók, de a kern mozgása most már háromdimenziós, ami a 3 dimenzión belüli függőségek jobb megragadását és az o utput dimenziók a konvolúció után.
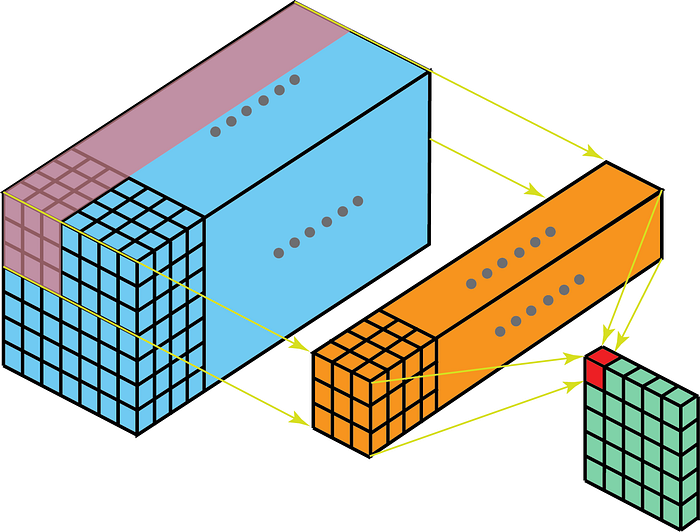
A konvolúcióban lévő kernel háromdimenziósan mozog, ha a kernelmélység kisebb, mint a jellemzőtérkép mélysége.
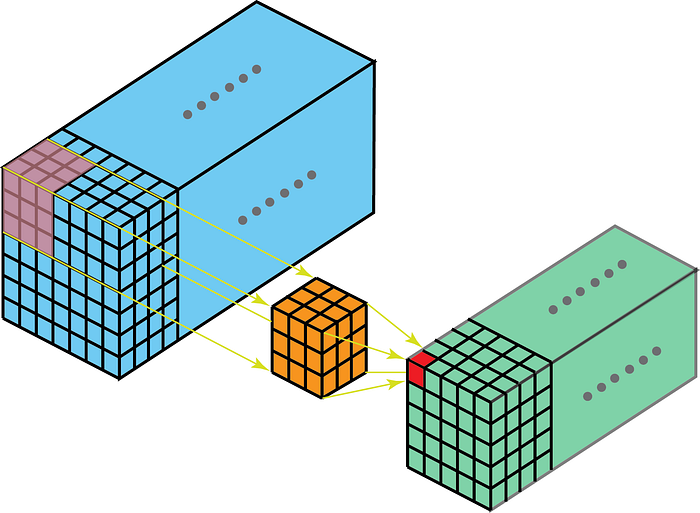
Másrészt a 2-D konvolúciók a 3D-adatokon azt jelentik, hogy a kern csak 2-D-ben fog haladni. Ez akkor történik, amikor a jellemzők térképének mélysége megegyezik a kernel mélységével (csatornák)
Néhány felhasználási eset a jobb megértés érdekében are – MRI vizsgálat, ahol meg kell érteni a képhalom közötti kapcsolatot; és egy alacsony szintű jellemzőkivonás az idő-térbeli adatokhoz, például videók a gesztusfelismeréshez, az időjárás-előrejelzéshez stb. (A 3D-s CNN-eket alacsony szintű funkciók elkülönítőjeként csak több rövid időközönként használják, mivel a 3D CNN nem képes hosszú távon rögzíteni térbeli-időbeli függőségek – erről bővebben ConvLSTM vagy egy alternatív perspektíva itt található. ) A legtöbb videoadatból tanuló CNN-modell szinte mindig a 3D CNN-t használja alacsony szintű szolgáltatás-kinyerőként.
A fent említett példában az 5-ös számra vonatkozóan – a 2D konvolúciók valószínűleg jobban teljesítenek, mivel minden csatornaintenzitást a birtokában lévő információ összesítéseként kezel, vagyis a tanulás majdnem ugyanaz, mint egy fekete-fehér képen. A 3D konvolúció használata ehhez viszont a csatornák közötti kapcsolatok megismerését eredményezné, amelyek ebben az esetben nem léteznek! (A 3 mélységű kép 3D konvolúciói is nagyon nem mindennapi kernel használható, különösen a használati eset esetében)
Remélem, hogy lekérdezése törölve lett!
Válasz
A 3D konvolúcióknak akkor kell lenniük, ha a térbeli jellemzőket három dimenzióban szeretné kivonni a bemenetből. A Computer Vision esetében ezeket általában volumetrikus képeken használják , amelyek 3D-sek.
Néhány példa a 3D renderelt képek osztályozására és orvosi kép szegmentálása